[NLP] 자연어처리 1. 기초, 워드클라우드
예전부터 배워보고 싶었던 자연어처리를 인프런 강의를 통해 듣게 되었는데 그 과정을 기록해보고자 한다 👏🏻
모두의 한국어 텍스트 분석과 자연어처리 with 파이썬 강의 | 박조은 - 인프런
박조은 | 파이썬 한국어 텍스트 분석과 자연어처리 워드클라우드 시각화, 형태소 분석, 토픽모델링, 군집화, 유사도 분석, 텍스트데이터 벡터화를 위한 단어 가방과 TF-IDF, 머신러닝과 딥러닝을
www.inflearn.com
박조은님 목소리가 엄청 차분하시고 발음도 좋으셔서 듣기 너무 편했음 - 추천 ❕
유료 강의라 전체 코드는 공개 안하고 일부 발췌하여 정리할 예정이다.
개발 환경 : Google Colaboratory
우선 데이터 분석에서 알아야 할 기초를 먼저 정리하고 뒤에 워드클라우드에 대해 정리할 것이다.
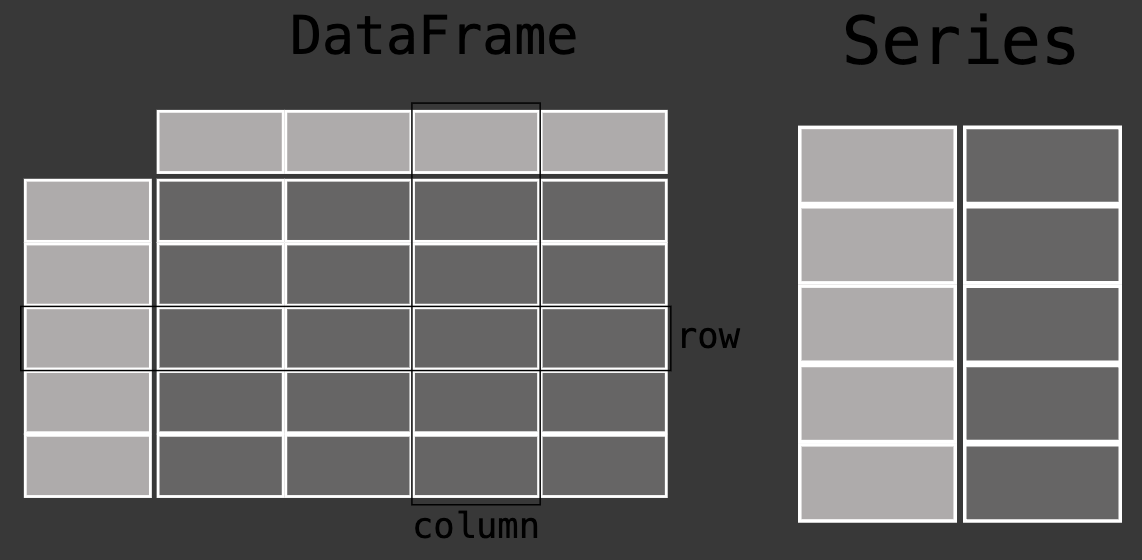
🎈DataFrame , Series 비교 (pandas)
- Series : 1차원 배열의 데이터를 다루는 자료구조 ( index, data )
- DateFrame : 2차원 배열의 데이터를 다루는 자료구조 ( row, column )
list =[ , , ,]
df = pd.DataFrame({"칼럼명" : list})
se = pd.Series(list)
🎈map, apply, applymap
: 함수 적용을 위한 함수(다중컬럼/단일컬럼)
- map() : 시리즈 df['칼럼명'].map(함수 or dict)
- apply() : 데이터프레임, 시리즈 df.apply(함수) | df['칼럼명'].apply(함수)
- applymap() : 데이터프레임 df.applymap(함수)
df['칼럼명'].map(lamdba x : len(x))
df['칼럼명'].apply(lamdba x : len(x))
df['칼럼명'].applymap(lamdba x : len(x))
*Lambda : 함수를 한 줄로 표현하는 익명 함수 기법 -> 외부에서 정의하는 것보다 훨씬 유리
-> : 기준으로 좌측이 입력데이터, 우측은 반환데이터이다.
🎈정규표현식 regex
: 특정한 규칙을 가진 문자열의 집합
주로 패턴으로 부르는 정규 표현식은 특정 목적을 위해 필요한 문자열 집합을 지정하기 위해 쓰이는 식이다.
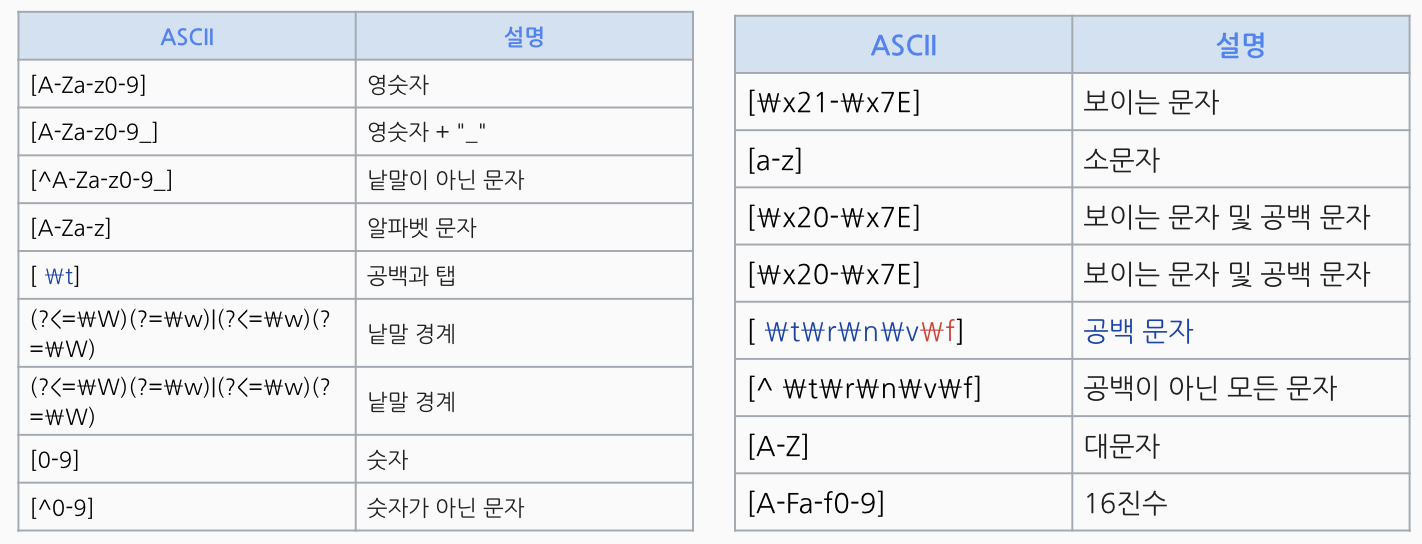
- [ ] : 일치시킬 문자 세트의 패턴
- [가나다] : 가 or 나 or 다 중에 하나를 포함하고 있는지
- [가-힣] : 한글 가부터 힣까의 문자 중 하나를 포함하고 있는지
- [0-9] : 0~9까지의 숫자 중 하나를 포함하고 있는지
- [^0-9] : 숫자를 포함하고 있지 않음
- [^가-힣] : 한글이 포함되어 있지 않음
- [가-힣+] : 한글이 하나 이상 포함되는지
간단한 예시로
#숫자 제거 *regex=True 시 적용
df['문서'].str.replace("[0-9]", "", regex=True) #숫자제거
df['문서'].str.replace("[^0-9]", "", regex=True) #숫자 외 제거
#영문자 제거
df['문서'].str.replace("[a-zA-Z]", "", regex=True)🎈워드클라우드
0. 한글 폰트 설치
!pip install koreanize_matplotlib #matplotlib에서 한글을 더 쉽게 쓰기 위함
!apt -qq -y install fonts-nanum #나눔폰트 설치#폰트 설정
import platform
if platform.system() == 'Windows':
# Windows 운영체제의 경우
font_path = r'C:\Windows\Fonts\malgun.ttf'
elif platform.system() == 'Darwin':
# macOS의 경우
font_path = r'/Library/Fonts/AppleGothic.ttf'
else:
# Linux 또는 기타 운영체제의 경우 (예: 'NanumBarunGothic')
font_path = r'/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf'
#라이브러리 로드
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import wordcloud import WordCloud # 워드클라우드 생성
import PIL import lmage # mask적용 시 이미지 활용
1. 데이터 로드 -> csv 나 json 불러오기
2. 결측치, 중복데이터 확인 -> df.isnull().sum() , df.duplicated(subset = ['칼럼'])
3. 단어 길이, 토큰 개수 확인 -> df['칼럼'].str.len() , df['칼럼'].str.split().str.len()
4. 모든 텍스트 하나로 만들기 -> new = " ".join(df['칼럼'])
5. 불용어 처리 -> 리스트로 정의하기 stopwords = [ '하지만', '너무' , '등', ...]
*불용어 : 실제 의미 분석을 위해 도움이 안 되는 단어
- 언어분류, 스팸 필터링, 캡션 생성, 자동태그 생성, 감정 분석, 텍스트 분류 관련 작업 ⭕️
- 기계 번역, 질문 답변 문제, 텍스트 요약, 언어 모델링 중 하나 ❌
6. 워드클라우드 생성
def display_word_cloud(data, width=1200, height=500):
word_cloud = WordCloud(font_path=font_path,
width=width,
height=height,
stopwords=stopwords,
background_color="white",
random_state=42
).generate(data)
plt.figure()
plt.imshow(word_cloud, interpolation="bilinear")
plt.axis("off")
plt.show()display_word_cloud(new)
+ 정규표현식 전처리 후 워드클라우드
# 한글과 영어만 남기기
df['칼럼2'] = df['칼럼'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 a-zA-Z]", " ", regex=True)
display_word_cloud(" ".join(df['칼럼2'])) # 하나로 통합 후 워드클라우드 생성
한글(초성, 모음, 완성형) 과 영어 알파벡 외의 모든 문자를 공백으로 대체한 것

+ 형태소 분석기로 특정 품사만 추출(pecab)
* 형태소 분석에 대해서는 다음에 정리할 예정입니당.
!pip install pecab
from pecab import PeCab
pecab = PeCab()
df['칼럼_명사추출'] = df['칼럼'].map(lamdba x : " ".join(pecab.nouns(x)))
display_word_cloud(" ".join(df['칼럼_명사추출']))
+ 마스크 처리
# 이미지 다운로드
import requests
mask_img_path = "http:// ~"
response = requests.get(mask_img_path)
# HTTP 요청이 성공했는지 확인합니다
if response.status_code == 200:
# 응답으로 받은 데이터를 파일로 저장합니다
with open("alice_mask.png", "wb") as file:
file.write(response.content)
mask_img = np.array(Image.open("alice_mask.png"))#마스크 적용된 워드클라우드 생성
def display_word_cloud_mask(data, stopwords=stopwords, mask=mask_img, width=1200, height=500):
word_cloud = WordCloud(font_path = font_path,
width=width,
height= height,
background_color="white",
mask = mask_img,
random_state = 42
).generate(data)
plt.figure()
plt.imshow(word_cloud, interpolation='bilinear')
plt.axis('off')
plt.show()
display_word_cloud_mask(" ".join(df_society['칼럼_명사추출']))
**자연어처리에서 text 표현하는 방법
자연어 처리의 전체적인 흐름을 파악하기에 좋은 사진인 것 같아서 가져와봤다!
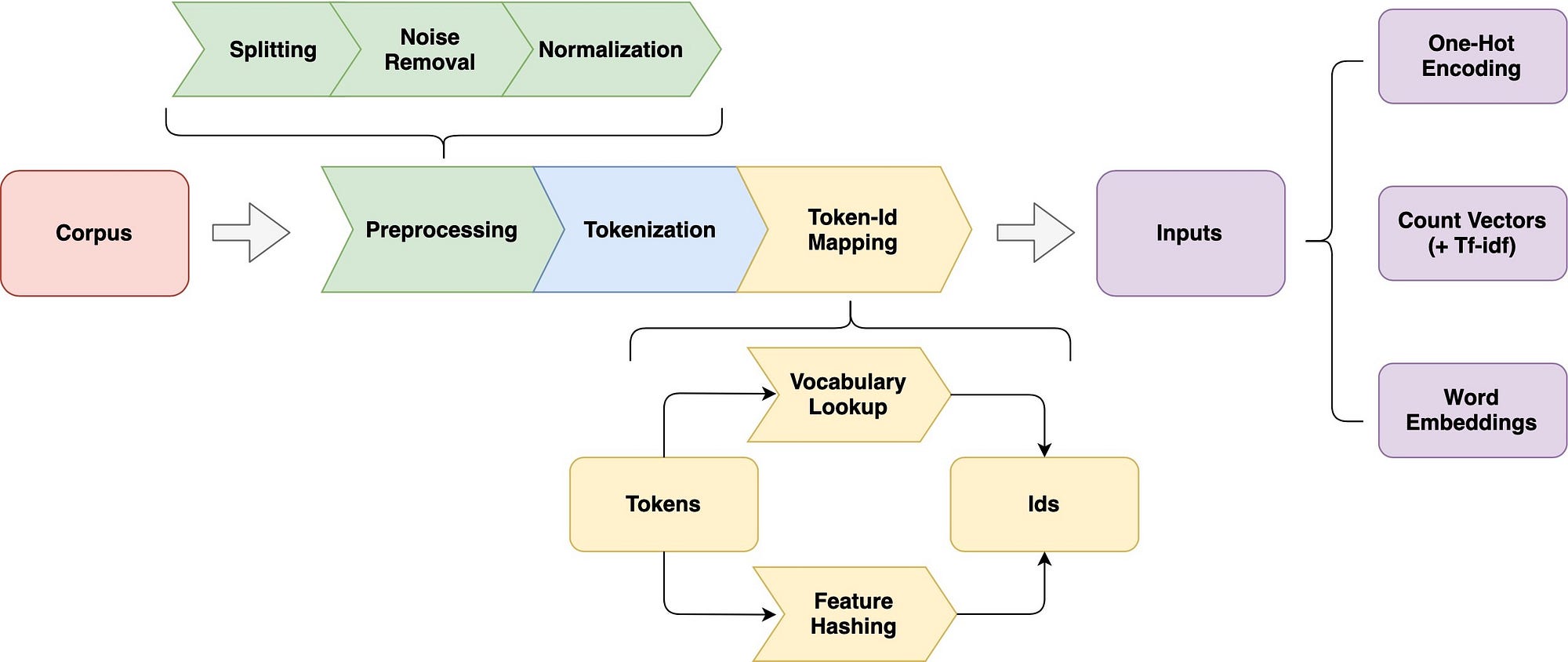
https://ko.wikipedia.org/wiki/%EC%A0%95%EA%B7%9C_%ED%91%9C%ED%98%84%EC%8B%9D
https://towardsdatascience.com/an-overview-for-text-representations-in-nlp-311253730af1