[NLP] 자연어처리 9. 트랜스포머 적용
Transformer란?
"Attention Is All You Need" (논문-구글 연구원)
-> 여기서 자연어 처리 분야에서 가장 혁신적인 모델 중 하나인 Transformer를 소개한다. Seq2Seq모델에서 사용되는 RNN, LSTM의 장기 의존성 문제와 병목 현상을 해결하고자 Self-Attention 메커니즘을 사용하여 Transformer 모델을 제안한다.
*Self-Attention 메커니즘 : 입력시퀀스의 각 원소들이 다른 원소들과 상호작용 -> 긴 시퀀스에서의 장기 의존성 문제를 해결할 수 있다.
Transformer 모델
: 인코더 + 디코더로 구성되며 입력시퀀스를 인코더에서 인코딩하고, 디코더에서 디코딩하여 출력 시퀀스를 생성한다.

인코더 : 입력 시퀀스를 받아서 순차적으로 처리한다.
입력시퀀스를 임베딩하여 임베딩 벡터 시퀀스를 생성하고 muit-head-attention과 feed forward를 반복하여 정보를 요약하는 과정을 통해 각 위치에 대한 context 정보를 생성하고 이 정보를 해당 위치에서 주변 정보들 간의 관계를 파악하는데 활용된다.
Bi-directioal EX)Bert - 다양한 NLP 태스크에 사용 - wordpiece 토크나이저
디코더 : 인코더에서 받은 정보와 이전에 생성된 출력을 입력으로 받아서 새로운 출력을 생성한다.
생성된 context 정보 기반으로 출력 시퀀스를 생성하는데 출력 위치마다 muit-head-attention과 출력에서 생성된 context 정보를 활용하여 이전 출력 정보를 예측하는 과정을 거치고 이후 feed forward 네트워크를 통해 이전 출력정보와 context 정보를 결합하여 현재 출력 예측값을 생성한다.
Uni-direction EX)GPT - 주로 문장 생성에 사용 - BPE 토크나이저
* Transformer에서 T5까지

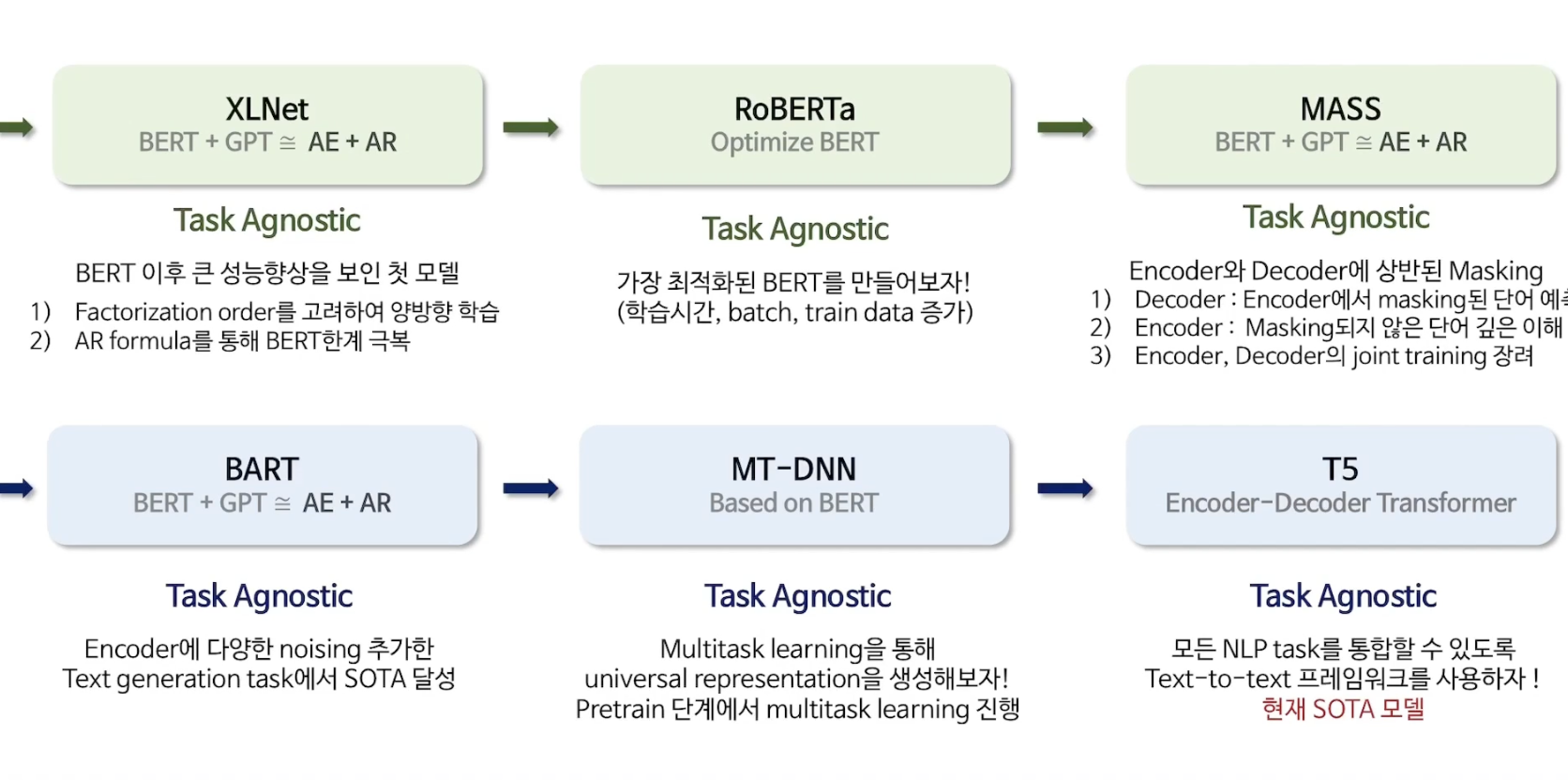
이제 데이콘 대회에 적용해보자 (최종)
*라이브러리 로드와 데이터 로드는 생략
0. 데이터셋 나누기
from sklearn.model_selection import train_test_split
dataset_train, dataset_val = train_test_split(train, test_size=0.33, random_state=42)
1. 파이토치의 Dataset 클래스를 상속받아 BERT 모델 학습을 위한 데이터셋 정의
class BERTDataset(Dataset):
def __init__(self, dataset, sent_key, label_key, bert_tokenizer):
...
def
...
def
...2. klue/bert-base 모델 사용
Auto Tokenizer - AutoModelForSequenceClassification - TrainingArgment - Trainer
1. Auto Tockenizer
from transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer
model_checkpoint = "klue/bert-base"
batch_size = 32
task = "nli"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, use_fast=True)#데이터셋 만들기
#각각 len 길이확인하면 30588개, 15066개, 9131개
data_train = BERTDataset(dataset_train, "title", "topic_idx", tokenizer)
data_val = BERTDataset(dataset_val, "title", "topic_idx", tokenizer)
data_test = BERTDataset(test, "title", None, tokenizer)2. AutoModelForSequenceClassification
: 입력으로 시퀀스를 받아서 다중 클래스 분류를 수행하는 모델을 생성하는 클래스
*from_pretrained()로 이전에 사전 훈련된 모델을 로드한다.
num_labels = len(np.unique(data_train.labels))
model = AutoModelForSequenceClassification.from_pretrained(model_checkpoint, num_labels=num_labels)
⚒️ BertModel
- BertEmbeddings : 입력텍스트의 각 토큰을 고차원 벡터로 변환
- BertEncoder : 입력데이터에 대한 인코딩 수행 - 여러 개의 BertLayer가 포함되어 있다.
- Dropout : 과적합 방지
- Linear : 최종 선형 레이어 여기서는 7개의 분류 클래스를 가정함
⚒️ load_metric()
: GLUE벤치마크 데이터셋 중 QNLI 데이터셋의 성능 측정 지표를 로드한다.
: 해당 데이터셋의 이름과 평가지표이름을 인자로 받아 해당 평가 지표 객체를 반환함
# metric.compute
# load_metric 위에서 따로 설치 해야 함 - datasets
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1)
return load_metric("glue", "qnli").compute(predictions=predictions, references=labels)3. TrainingArgment
: fine-tuning을 위한 모델 학습을 설정한다.
# TrainingArguments
metric_name = "accuracy"
args = TrainingArguments(
"test-nli",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=3,
weight_decay=0.01,
load_best_model_at_end=False,
metric_for_best_model=metric_name,
)# AutoModelForSequenceClassification.from_pretrained
def model_init():
return AutoModelForSequenceClassification.from_pretrained(model_checkpoint, num_labels=num_labels)4. Trainer
: 데이터 로딩, 전처리, 모델 학습 및 평가 등의 작업을 자동으로 처리해주며 다양한 모델 아키텍처를 학습시킬 수 있다.
# Trainer
trainer = Trainer(
model_init=model_init,
args=args,
train_dataset=data_train,
eval_dataset=data_val,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
trainer.train() #학습
trainer.evaluate() #평가
3. 예측
y_pred = trainer.predict(data_test)
이렇게 예측한 결과를 데이톤에 제출해보면 0.7~8 정도로 상위권에 위치하는 것을 알 수 있다.
그럼 트랜스포머를 이용해서 한국어 GPT2 모델로 문장 생성하는 것도 간단하게 해보자
: 다음 단어를 잘 예측할 수 있도록 학습하여 문장 생성에 최적화되어 있으며 한국어 디코더 언어모델이다. 이모지도 추가하여 학습시켰다.
토크나이저 설정
# PreTrainedTokenizerFast
from transformers import PreTrainedTokenizerFast
tokenizer = PreTrainedTokenizerFast.from_pretrained("skt/kogpt2-base-v2",
bos_token='</s>', #시작문자
eos_token='</d>', #끝문자
unk_token='<unk>', #알수없는 문자
pad_token='<pad>', #패딩에 사용
mask_token='<mask>') #마스킹 토큰
len(tokenizer)tokens = tokenizer.tokenize(raw_text) #토크나이저 적용, _이 붙은 건 단어의 시작을 의미
token_ids = tokenizer.convert_tokens_to_ids(tokens) # 토큰 목록 -> 토큰아이디로 반환
converted_tokens = tokenizer.convert_ids_to_tokens(token_ids) # 토큰아이디 -> 토큰
converted_text = tokenizer.convert_tokens_to_string(converted_tokens) # 토큰 목록 -> 문장
tokenizer.encode(raw_text) # 문장 -> 토큰아이디 = tokenize() + convert_tokens_to_ids()
모델 불러오기
# GPT2LMHeadModel.from_pretrained
# skt/kogpt2-base-v2
import torch
from transformers import GPT2LMHeadModel
model = GPT2LMHeadModel.from_pretrained('skt/kogpt2-base-v2')
text = '근육이 커지기 위해서는'
input_ids = tokenizer.encode(text, return_tensors='pt')
gen_ids = model.generate(input_ids,
max_length=128,
repetition_penalty=2.0,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.bos_token_id,
use_cache=True)
generated = tokenizer.decode(gen_ids[0])
함수로 만들기
def generate_text(text):
input_ids = tokenizer.encode(text, return_tensors='pt')
gen_ids = model.generate(input_ids,
max_length=512,
repetition_penalty=5.0,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.bos_token_id,
use_cache=True)
generated = tokenizer.decode(gen_ids[0])
return generated
text = '오늘의 점심 식사는?'
generate_text(text)
이런 식으로 구현해볼 수 있다. 이렇게 했을 때 제대로 잘 나오지는 않는 것 같지만 허깅페이스에서 제공하는 많은 모델들을 한 번씩 적용해보며 연습해보면 좋을 것 같다.
이것으로 "모두의 한국어 텍스트 분석과 자연어처리 with 파이썬" 에 대한 강의 정리를 마치고 다음엔 강의에서 배운 것들을 다른 데이콘 대회에 적용해보며 상위권의 점수를 얻을 수 있도록 해봐야겠다.
https://www.youtube.com/watch?v=v7diENO2mEA
https://dacon.io/competitions/official/235747/overview/description
https://huggingface.co/klue/bert-base
https://huggingface.co/skt/kogpt2-base-v2
모두의 한국어 텍스트 분석과 자연어처리 with 파이썬 강의 | 박조은 - 인프런
박조은 | 파이썬 한국어 텍스트 분석과 자연어처리 워드클라우드 시각화, 형태소 분석, 토픽모델링, 군집화, 유사도 분석, 텍스트데이터 벡터화를 위한 단어 가방과 TF-IDF, 머신러닝과 딥러닝을
www.inflearn.com