파이썬 기반 빅데이터 실습 프로젝트
일시 : 2022.01.25.(화) 09:00 ~ 18:00
주제 : 국민청원 분석 (팀프로젝트)
<과정>
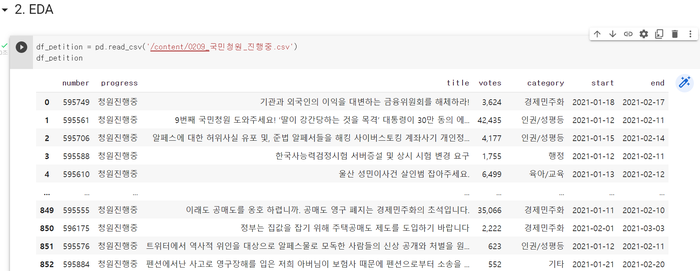
-국민청원 중 현재 청원진행 중인 엑셀파일을 read해준다.
df_petition = pd.read_csv('/content/0209_국민청원_진행중.csv')
df_petition
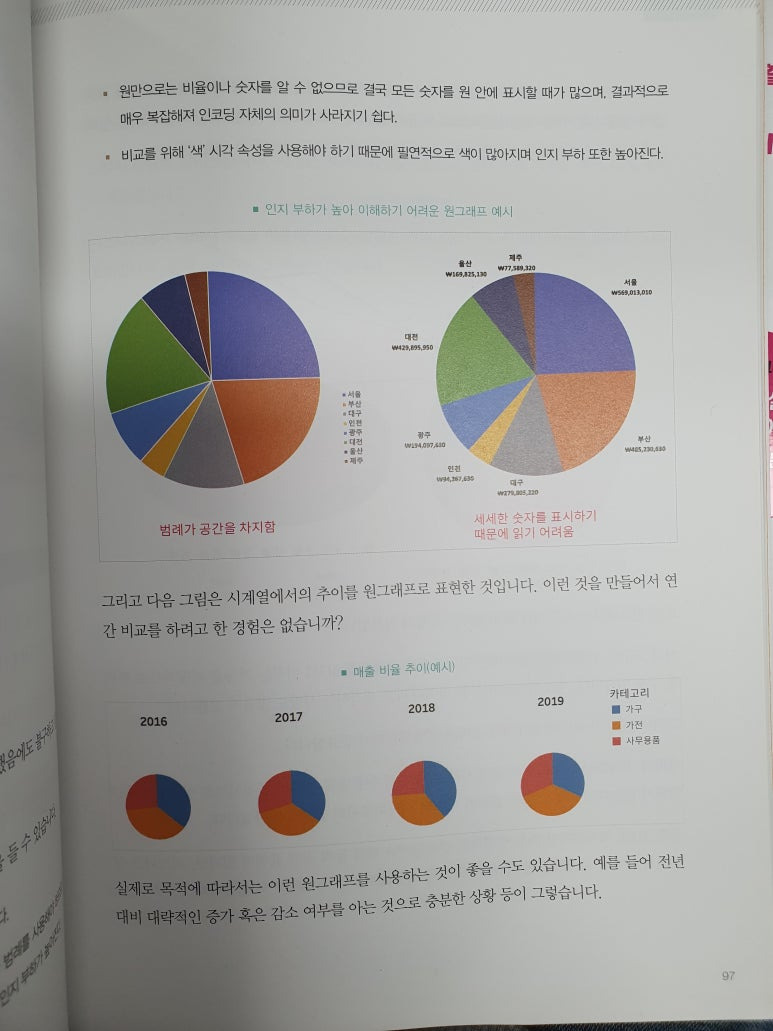
이 과정은 EDA(Exploratory Data Analysis, 탐색적 데이터 분석)인데 EDA의 키워드는 '탐색과 분석'이라고 할 수 있다.
아래는 EDA뿐 아니라 데이더 분석에서 중요한 기술 세 가지이다.
1) raw data의 column과 row 의 의미 파악
2) 결측치 처리 ( 데이터필터링 )
3) 시각화
지금 주어진 raw data로 전처리 과정을 통해 결측치를 없애고 우리고 구하고자 하는 결과에 맞도록 데이터를 분석하는 것이다.
엑셀 파일을 read한 raw data를 살펴보면 먼저 데이터의 정보를 알아야 한다.
df_petition.info()
그리고 결측치를 확인하는데
sns.heatmap(df_petition.isnull(), cbar=False)
이렇게 하면 결측치를 시각화하여 나타내준다.
그리고 우리가 어떤 결과를 도출하고 싶은지를 정해야 한다.
column의 종류를 보면서 몇 가지를 생각해보자
numder - 몇 개의 청원 수가 있는지 나타내 준다 -> 854
process - 청원상태인데 우리는 '청원진행중'만 뽑아와서 큰 의미는 없다.
votes - 투표 수를 나타내는 것으로 많고 작음으로 사람들의 관심도를 알 수 있다.
category - 청원 종류이고 총 17개로 어떤 종류에 사람들이 많이 청원을 했는지 알 수 있다.
date - 어떤 날짜에 가장 많은 청원을 했는지, 최근에 어떤 category의 청원이 많이 등록되었는지 등을 알 수 있다.
우선 짧은 시간에 데이터를 분석하고 시각화까지 해야 했기 때문에 복잡한 분석보다는 전체적인 분석을 하였다.
먼저, 빈도 수가 가장 많은 카테고리 상위 5개를 고르고
카테고리 별로 명사 추출을 하여 가장 많이 나온 단어를 5개 고른다.
(이때, 의미없는 단어는 제외한다. ex. 것, 만, 관련 등)
상위 5개 단어를 시각화하고, 워드클라우드로 나타내고
마지막 가장 많이 나온 단어 1개에 관련된 청원 제목을 3개씩 뽑아 요약한다.
카테고리 별 가장 이슈가 되는 주제의 청원이라고 생각할 수 있다.
마지막으로 그 요약한 청원 내용에 대해 해결책을 제시하는 것으로 마무리한다.
※참고-대시보드 설계와 데이터 시각화
대시보드 설계와 데이터 시각화 책 참고
1) 카테고리 별 빈도 수가 많은 순서대로 시각화
px.histogram(df_petition, x = 'category', color = 'category').update_xaxes(categoryorder = "total descending")
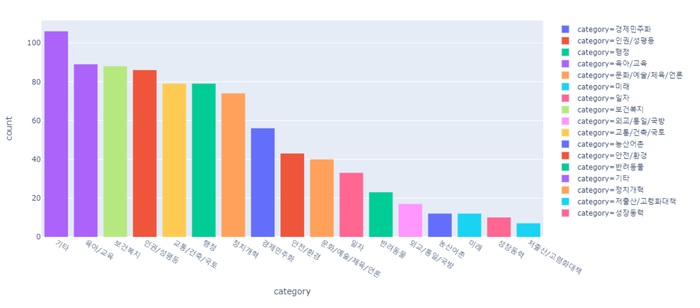
2) 가장 많은 5개 카테고리 뽑기 ( 기타 제외)
1. 육아/교육
2. 보건복지
3. 인권/성평등
4. 교통/건축/국토
4. 행정
3) 카테고리 별로 명사 추출하여 가장 많이 나온 단어 5개 뽑기
# 제거할 명사 리스트에 포함된 단어 제거
for rem in remove:
count.pop(rem)
# 명사 빈도 상위 5위
print(keyword + " 명사 빈도 상위 5위")
count = count.most_common(5)
count_dict = dict(count)
print(count_dict)
<결과 예시_교통/건축/국토>

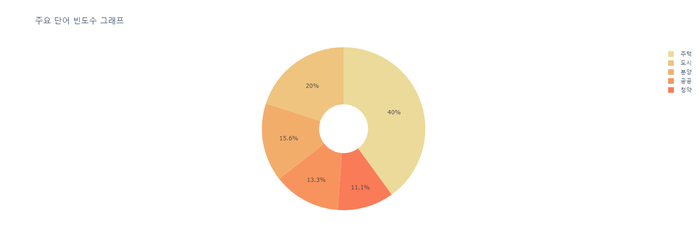
4) 빈도 높은 단어 5개 시각화 ( 도넛 모양 )
# 명사 빈도 상위 5위를 데이터프레임으로 변환
col_name = ['단어', '빈도수']
df_most_common = pd.DataFrame(count, columns = col_name)
display(df_most_common)
# 위에서 만든 데이터프레임을 바탕으로 그래프 출력
display(px.pie(df_most_common, values='빈도수', names='단어',
title='주요 단어 빈도수 그래프',
color_discrete_sequence=px.colors.sequential.Oryel,
hole=.3 # 도넛 설정
))
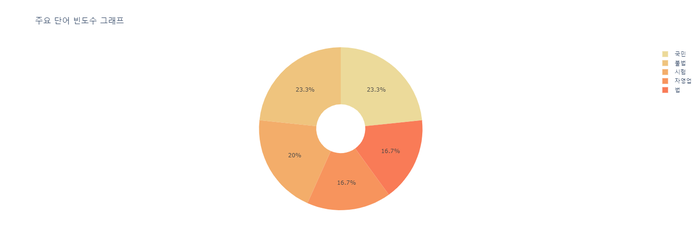
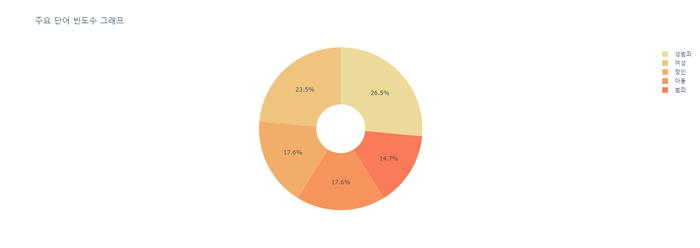
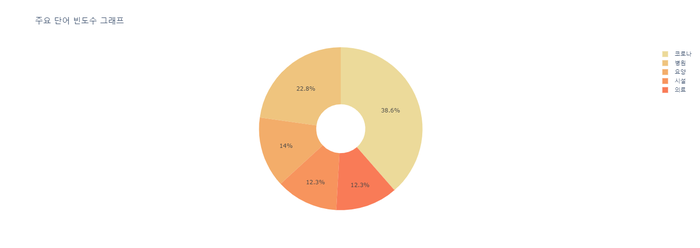
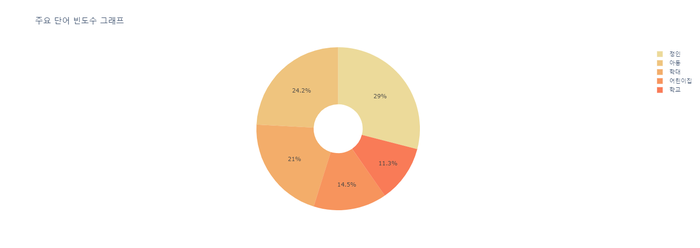
순서 : 교통/건축/국토 -> 행정 -> 인권/성평등 -> 보건복지 -> 육아/교육
※참고
데이터 시각화 디자인 책 참고
+ 워드클라우드로 나타내기





순서 : 인권/성평등 -> 행정 -> 보건복지 -> 육아/교육 -> 주택/건축/국토
5) 카테고리 별 가장 빈도 수 높은 단어와 관련된 청원 3개씩 추출하기
# 최빈 단어 관련 청원 중 투표수 상위 3위
word = df_most_common.iloc[0]['단어']
new_data = etc_data[etc_data['title'].str.contains(word)]
new_data = new_data.sort_values(['votes'], ascending = [False]).head(3)
display(new_data)<결과 예시_교통/건축/국토>

이런 식으로 3개의 청원을 하나로 요약하여 결과를 도출하였다.
▷육아 / 교육 : 사회적으로 많은 이슈가 되었던 정인이 사건에 관해 여전히 사람들이 관심을 쏟고 있다.
▶보건복지 : 코로나로 인한 의료진들의 고통 및 병원(특히 요양 병원) 환자의 인권 관련 문제에 관심이 많다.
▷인권/성평등 : 사람들은 남초 커뮤니티의 성범죄와 관련된 이슈에서 많은 호소를 하고 있다.
▶행정 : 다양한 업계에 종사하고 있는 국민 모두가 어려움을 겪고 있다.
▷교통/건축/국토 : 실거주할 주택의 공급이 수요에 못 미쳐 문제가 발생한 상황을 확인했다.
<전체 코드 _ 파이썬>
import pandas as pd
from konlpy.tag import Mecab
from collections import Counter
# Mecab 객체 생성
mecab = Mecab()
# 명사 추출할 카테고리 설정
keyword = '육아/교육'
# 제거할 명사 리스트
remove = ['사건', '관련']
# 설정한 카테고리의 데이터들만 따로 데이터프레임에 저장
etc_data = []
etc_data = df_petition[df_petition['category']==keyword]
print(keyword + " 카테고리 자료")
display(etc_data)
# 명사 리스트 생성
nouns = []
for title in etc_data['title']:
noun = mecab.nouns(title)
nouns.extend(noun)
# 명사 빈도 카운트
count = Counter(nouns)
# 제거할 명사 리스트에 포함된 단어 제거
for rem in remove:
count.pop(rem)
# 명사 빈도 상위 5위
print(keyword + " 명사 빈도 상위 5위")
count = count.most_common(5)
count_dict = dict(count)
print(count_dict)
# 명사 빈도 상위 5위를 데이터프레임으로 변환
col_name = ['단어', '빈도수']
df_most_common = pd.DataFrame(count, columns = col_name)
display(df_most_common)
# 위에서 만든 데이터프레임을 바탕으로 그래프 출력
display(px.pie(df_most_common, values='빈도수', names='단어',
title='주요 단어 빈도수 그래프',
color_discrete_sequence=px.colors.sequential.Oryel,
hole=.3 # 도넛 설정
))
# 최빈 단어 관련 청원 중 투표수 상위 3위
word = df_most_common.iloc[0]['단어']
new_data = etc_data[etc_data['title'].str.contains(word)]
new_data = new_data.sort_values(['votes'], ascending = [False]).head(3)
display(new_data)<느낀점>
이 실습은 원래 트롤링부터 시작하는 것이었는데 중간에 오류가 발생하여 엑셀파일을 read하는 것으로 raw data 를 가져왔다.
실제 데이터를 가지고 실습을 해본 것은 처음이기 때문에 아주 간단한 분석도 헤맸던 것 같다.
다음 실습에는
1. 트롤링하는 법
2. 시각화 그래프를 데이터 특성에 맞게 다양하게 구사
할 수 있기를 기대한다.
https://colab.research.google.com/drive/1p-ozTOfqjUUR61czFg9Rwi1irDNnBpg4?usp=sharing